

데이터 분석의 단계별 목적 이해하기 (분석 싸이클 이해)¶
데이터 싸이언티스트?/애널리스트?/엔지니어?/비즈니스고객? 관점에서:¶
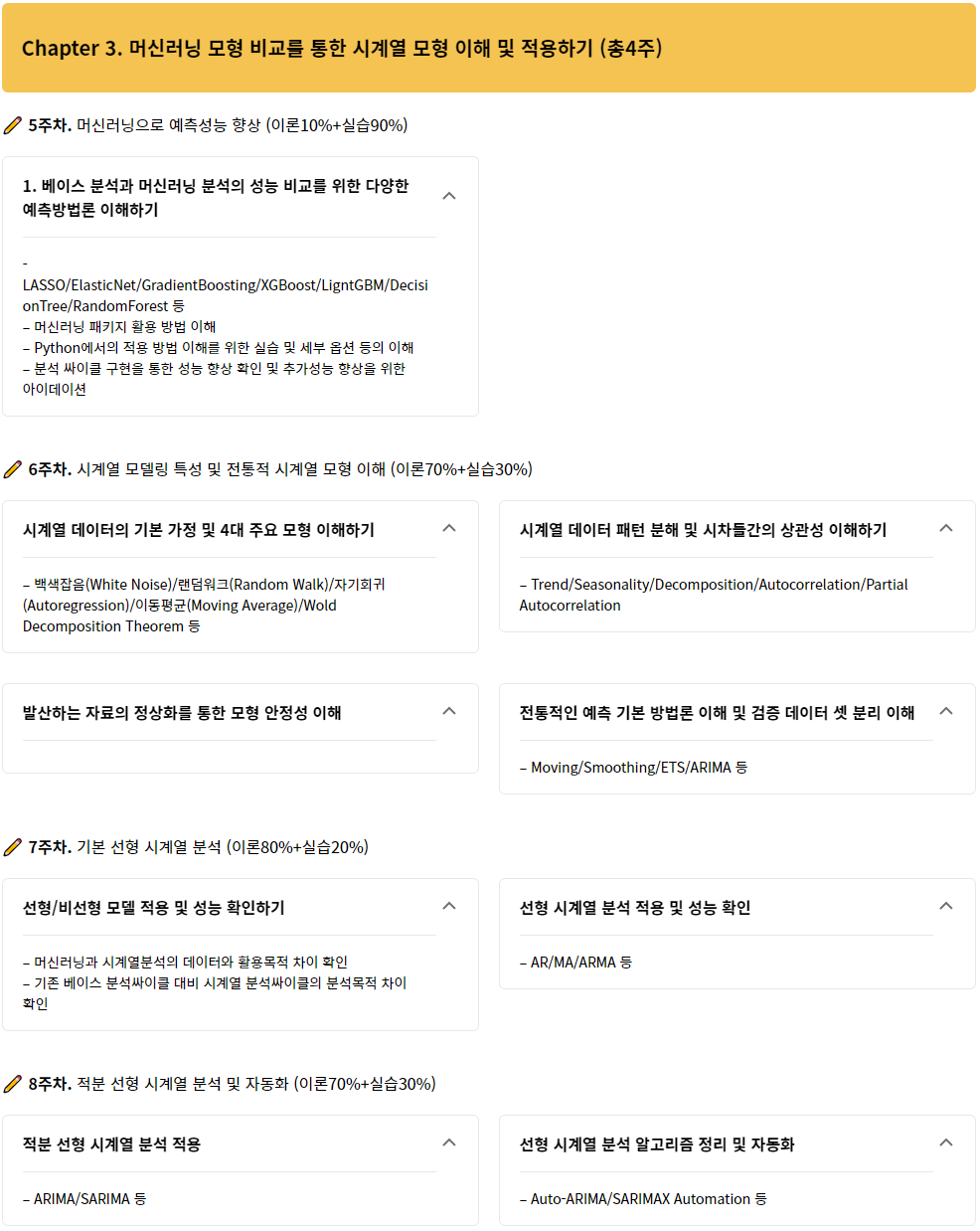
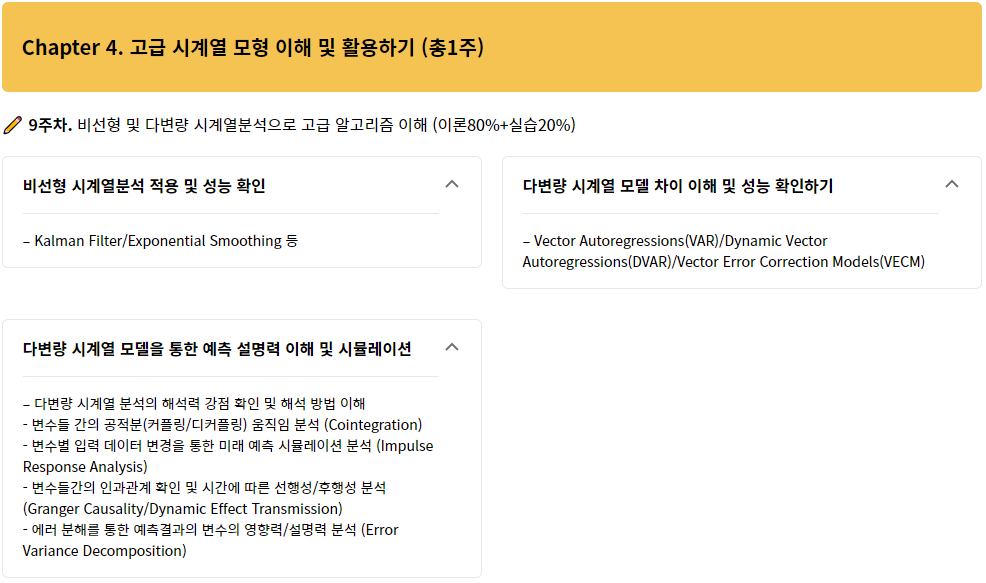
데이터수집: 소스별 데이터 추출 및 저장(Loading)
데이터전처리: 기초통계(Descriptive Statistics) + 붙이기(Curation) + 없애기(Remove) + 채우기(Fill) + 필터(Filter) + 변경하기(Transform)
데이터정리: 데이터한곳에담기(Data Warehouse) + 바꾸기및정리(Data Mart) + 분리(Data Split)
데이터분석: 기초통계(Descriptive Statistics) + 모델링(Algorithm) + 검증(Evaluation) + 에러분석(Error Analysis)
결과정리: 시각화(Visualization/Dashboard) + 의사결정(Decision Support) + 지식화(Knowledge) + 공유(Reporting)
데이터분석 현실 관점에서:¶


데이터분석 현실요약:
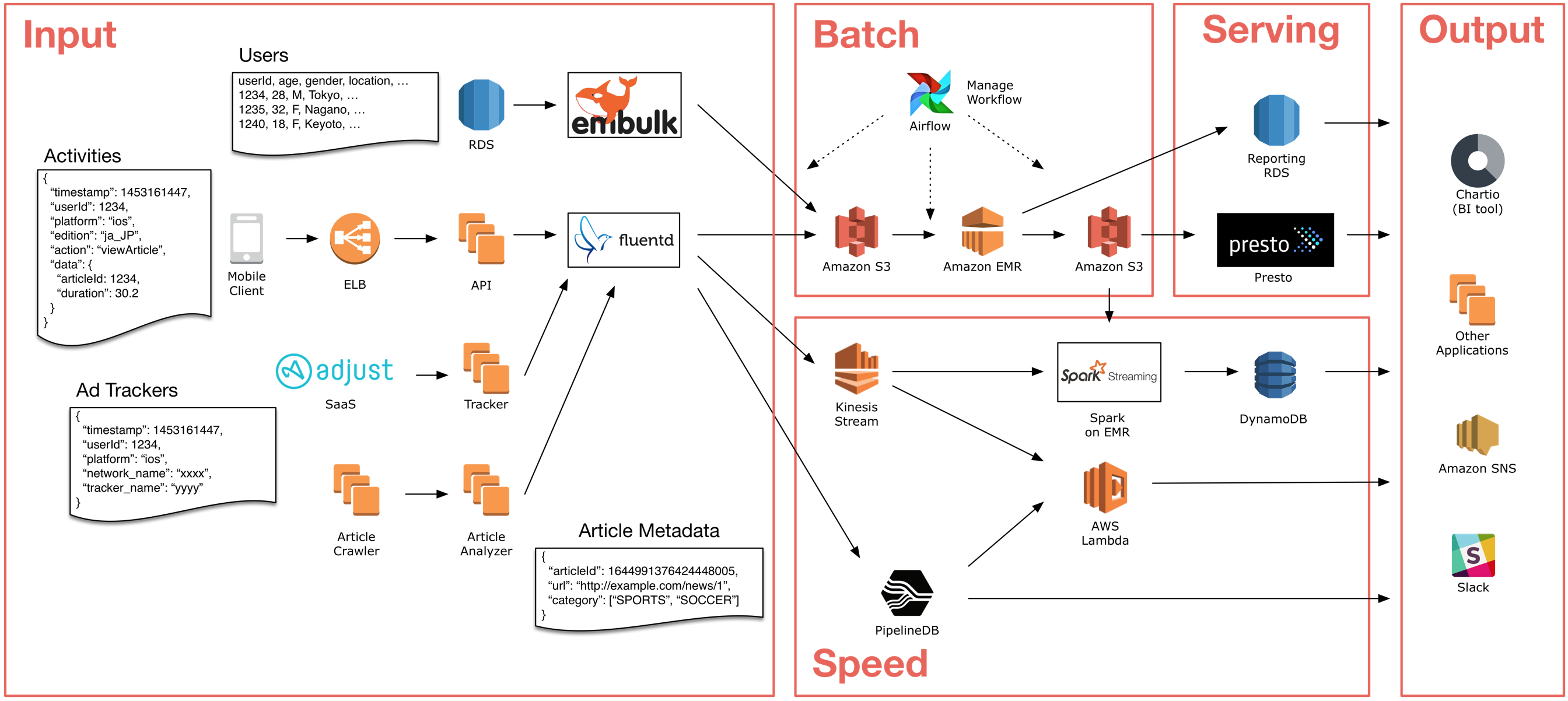
“데이터분석 설계(1단계)”는 “모델링(2단계)”보다 훨씬 중요합니다. 그리고 “분석종료(3단계)”는 또다른 새로운 시작입니다
예시1) “퇴사할 사람을 찾아주세요” vs “입사할 사람을 찾아주세요“
예시2) “삼성전자 주식을 사야 할까요 말아야 할까요?” vs “내일 삼성전자 주식은 얼마일까요?”
요구사항(질문) 예시:
“아이폰 고객은 왜 갤럭시 고객보다 충성도가 높은지 분석해봐~” 라고 질문을 다 듣기도/이해하기도/생각하기도 전에 프로젝트가 시작됩니다
“AI를 활용해서 생산공정의 이상을 조기 탐지하고 비용을 줄여봐~” 라고 질문을 다 듣기도/이해하기도/생각하기도 전에 프로젝트가 시작됩니다
“타겟 마케팅을 하기위해 누구한테 프로모션을 해야하는지 알려줘봐~” 라고 질문을 다 듣기도/이해하기도/생각하기도 전에 프로젝트가 시작됩니다
문제정의: 무엇을 분석할지 정한다
무엇을 분석할지 각자 생각이 모두 다르다(솔직히 아무도 모른다)
무엇을 분석할지 모르지만 일단 도구(R? Python? 플랫폼? 아마존? 외주?)부터 마련한다
무엇을 분석할지 모르지만 완료일정과 계획이 준비가 되어있다
어쨌건 있다고 생각하고 시작한다
(데이터분석 프로젝트는 이미 착수했다고 보고가 되었다)데이터수집: ~~소스별 데이터 추출 및 저장(Loading)~~
데이터 PC에 있는줄 알았는데 A4용지에 있어서 누구 시켜서 파일로 바꾼다
데이터를 구했는데 빅데이터는 아니고 그냥 엑셀 파일 몇개다
데이터 파일을 열었더니 다 빈칸이고 딱봐도 오타 투성이다
근데 이 데이터로 충분한지 아무도 모르지만 어쨌건 (있는줄/충분한줄 알았는데) 시작한다
(빅데이터를 기반으로 한 데이터 수집이 완료가 되었다고 보고가 되었다)데이터전처리: ~~기초통계(Descriptive Statistics) + 붙이기(Curation) + 없애기(Remove) + 채우기(Fill) + 필터(Filter) + 변경하기(Transform)~~
무엇을 분석할지 모르고 데이터는 없지만 전처리에 돌입한다
일단 이상해 보이는 데이터를 다 지워본다 (남는게 없다..)
임의로 데이터를 채워본다 (어짜피 아무도 모르니까..) 할게 많을 줄 알았는데 별로 할게 없음을 깨닿는다
(데이터가 무결점으로 잘 준비되어 있다고 보고가 되었다)데이터정리: ~~데이터한곳에담기(Data Warehouse) + 바꾸기및정리(Data Mart) + 분리(Data Split)~~
(대부분 개인PC로 충분하겠지만) 일단 서버/플랫폼에 데이터를 올린다
(뭔가 중요한걸 해야할것 같은데..) 서버/플랫폼 사양정도 체크해보며 있는다
(데이터 플랫폼에 데이터가 이관되고 곧 분석에 착수할거라고 보고가 되었다)데이터분석: ~~기초통계(Descriptive Statistics) + 모델링(Algorithm) + 검증(Evaluation) + 에러분석(Error Analysis)~~
무엇을 분석하고 무슨 데이터를 사용해야 되는지 모르지만 분석을 시작한다
기초통계는 사람수?클릭수? 등 “횟수(count)”면 충분하다
도구(R? Python? 플랫폼? 아마존? 외주?) 활용/쪼아서 제일 최신 알고리즘을 적용해보려 살펴본다
(뭔가 안되면..) 우선 1차 회귀분석? 상관관계? 어디서 들어본걸 해서 그림부터 그려본다
(뭔가 중요한 단계인것 같은데..) 더이상 할수 있는게 없음을 깨닿는다
(분석이 완료되어 인싸이트가 곧 쏟아질 것이라고 보고가 되었다)결과정리: ~~시각화(Visualization/Dashboard) + 의사결정(Decision Support) + 지식화(Knowledge) + 공유(Reporting)~~
무엇을 분석하고 무슨 데이터를 사용하고 무슨 결과가 있는진 모르겠지만 결과를 정리한다
(완료일정이 내일이라 퇴사/퇴학이 필요한게 아닌지 잠이 오지 않는다)
(신기한건 모든 단계는 작동/구현되었고 각 단계 개발자들은 성과를 보고한다)
(Kaggle과 데이터분석은 다름을 알게된다)
데이터 싸이언티스트 실무 관점에서:¶
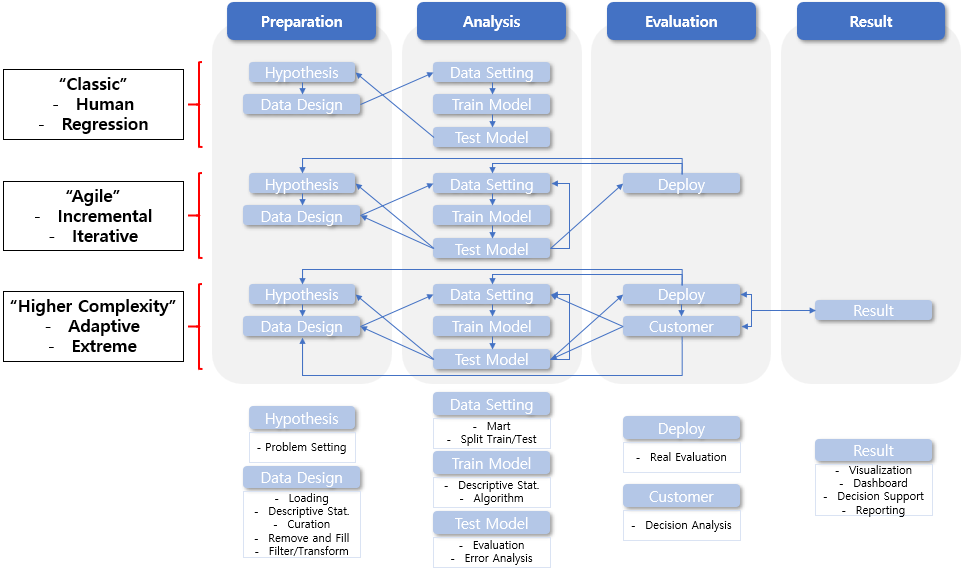
문제정의: 무엇을 분석할지 정한다
문제정의가 없으면 분석은 시작할 필요가 없다
문제정의에 많은 고민을 해야 한다
문제정의에 모든 구성원이 동의할 수 있도록 끊임없이 커뮤니케이션 해야 한다
1회성이 문제정의가 아니라 필요시 끊임없이 진화/변경시켜야 한다
데이터수집: 소스별 데이터 추출 및 저장(Loading)
데이터가 없으면 분석은 시작할 필요가 없다
문제 답의 보기후보가 데이터에 없으면 분석을 시작할 필요가 없다(어떤 연령이 TV를 보는지 알고 싶은데 데이터에 연령이 없으면 불가)
알고리즘/기술보다 데이터수집부터 시작하기 위한 작업을 착수해야 한다 데이터는 많을수록 좋지만 양보다(Row) 질(Column)을 늘려야 분석을 한 의미가 생긴다 보기가 데이터에 없으면 문제정의부터 새롭게 수정해야 한다
Loading 목적: 각 소스별로 데이터를 수집함
데이터전처리: 기초통계(Descriptive Statistics) + 붙이기(Curation) + 없애기(Remove) + 채우기(Fill) + 필터(Filter) + 변경하기(Transform)
Descriptive Statistics 목적: 하기 4개의 전처리 의사결정을 위한 기준으로 주로 활용
Curation 목적: 각 소스별 데이터를 하나의 Database로 붙임
Remove & Fill 목적: 데이터 오류를 제거하가나 비어있는 데이터를 채움
Filter 목적: 분석범위에 관련된 보기(Feature)들만을 추려냄
Transform 목적: 사람이 이해가 가능한 방식으로 데이터 자체를 변경함
데이터정리: 데이터한곳에담기(Data Warehouse) + 바꾸기및정리(Data Mart) + 분리(Data Split)
데이터수집/전처리/정리 까지 전체 업무의 80% 이상을 차지한다
1회성 수집/전저리/정리로 끝나지 않고 끊임없이 업데이트하고 진화시켜야 한다(이는 분석알고리즘이 해주지 않는다)
Data Warehouse 목적: 전처리 단계를 거친 1개의 Database를 주로 보관 및 무결점 유지 목적
Data Mart 목적: Warehouse를 변경하지 않고 복사하여 조금 더 목적에 맞게 전처리를 거침
Data Split 목적: 주로 과거(Train Data)와 미래(Test Data)를 구분하여 저장/알고리즘에 활용
데이터분석: 기초통계(Descriptive Statistics) + 모델링(Algorithm) + 검증(Evaluation) + 에러분석(Error Analysis)
수학적으론 어려울 수 있지만 수동적으로 대응/활용이 가능하다
알고리즘(또는 기계)은 정해진 검증수단을 따를뿐 우리의 문제에 관심이 없다
각 알고리즘의 사용 목적에 대한 명확한 이해와 결과해석을 집중해서 습득해야 한다
어떤 알고리즘 성능 뛰어난지 검증(Evaluation)은 결국 사람이기에 많은 고민을 해야 한다 알고리즘 적용시작이 중요한게 아니라 언제 끝내야 하는지 고민해야 한다Descriptive Statistics 목적: 어떤 분석 알고리즘을 선정할지 또는 Input/Output 형태를 결정하는 기준으로 활용
Algorithm 목적: Input/Output의 형태 또는 분석목적에 따라 정해지는 편
Evaluation 목적: 현 알고리즘 성능 확인 및 다음 업데이트를 위한 기준 설정
Error Analysis 목적: 모든 데이터의 패턴/특징을 알고리즘이 반영하고 있음을 이해하기 위한 기준
결과정리: 시각화(Visualization/Dashboard) + 의사결정(Decision Support) + 지식화(Knowledge) + 공유(Reporting)
0~4 단계를 무한대로 반복 및 각 단계를 업데이트하며 인싸이트를 뽑아낼 수 있어야 한다
Visualization/Dashboard/Decision/Knowledge/Reporting 목적: 주로 고객에 맞춘 설명력을 제공하기 위함으로 일반화된 방향은 없음
분석을 이해하고 공감하는 자세 및 방향¶
“거짓말의 3가지 종류: 거짓말, 새빨간 거짓말, 그리고 통계 (by 마크 트웨인)”
전혀 이해되지 않는 어려운 수식을 나열하고 분석을 하여 결론을 내버렸는데 아무리 생각해도 내 상식과는 다를 경우가 자주 있다!
어떤 데이터를 어떤 방식으로 가공했고, 어떤 방법으로 도출했는지 아이들에게 충분히 가르칠 수 있으나, 전문가라는 사람이 일반 성인들에게 자신의 측정 방식을 제대로 이해시킬 수 없다는건 수상한것이 아닌가?
세상 사람들은 뭔가 복잡하고 어려운 과학기법을 썼다고 하면 이상하리만치 맹신하는 경향이 있다
통계의 한계¶
모집단(Population)의 특성을 통계로 설명하는 것은 굉장히 괜찮은 접근이다
표본(Sample)과 모집단(Population)의 특성이 꼭 같을 수는 없고 상당히 위험한 발상이다
표본을 통해 모집단을 추정하려는 방식과 모집단 자체의 특성을 분석하려는 방식 중 무엇이 좋은건지는 누구도 알 수가 없다
하나의 표본으로 모집단의 평균을 정확히 알 수는 없지만 추측은 가능하다
빅데이터라 하여도 데이터 분석이 필요한 이유는 빅데이터도 결국 표본일 가능성이 높기 때문이다
통계는 결국 표본의 통계 특성을 통해 모집단의 통계 특성을 “추측”하는 것이다
추측이기에 장담할 수 없고 확률이론을 가져와 얼추 95% 정도 맞을 가능성으로 추정을 하지만 5%의 틀렸을 가능성은 반드시 존재한다
내가 올바른 추정을 했다 하더라도 95%의 신뢰구간이 너무 커서 별로 쓸모가 없을 수도 있다
통계의 큰 함정: 만약 Sample을 추출하는 과정이 틀렸으면 중심극한정리(Central Limit Theorem)는 동작하지 않는다
이상적인 Sample 추출은 거의 불가능하다
Sample이 왜곡되어 있으면 통계분석 결과는 과학적으로 유의미하지 않을 수 있다
현실은 의도적인 편향된 Sample로 인한 결과물들을 믿으며 자주 접하고 살고 있다는 것이다
모집단이 시간에 따라 변화한다면, 과거에 추출한 샘플은 현재를 설명하지 못한다
시간의 흐름에 따른 모집단의 변화를 추정하면 좋겠지만.. 이건 불가능이다
현실은 분석결과를 과거/현재/미래에도 그럴거라고 믿음으로 살고 있다는 것이다(단지 과거 결과일 뿐이다)
많은 전문가들이 통계의 한계를 전문적인 이유로 설명하지 못하더라도 본능적으로 왜곡될 수 있음을 인지하고 있다
일반인들이 통계정보를 믿기 힘든 것은 어쩌면 당연한 일이다
통계의 강점¶
통계는 대규모 조사의 어려움을 획기적으로 줄일 수 있다
통계는 다소 개인차가 있는 어떤 집단에 대해서도 공통적인 특징을 추출할 수 있다
일반인/환자들의 약물 효능이 통계적으로 유의미한지 비교를 통해 인간에게 통상적으로 미치는 특성을 해석할 수 있다
통계적 추정을 하는데 말고 다른 방법으로 활용이 가능하다
내일의 주식 가격 예측은 불가능하지만 통계를 통해 주가의 적정 범위를 추정하는 것은 가능하다(주식에 어떤 변화가 발생하지 않을 경우)
시장의 변화나 사고 발생에 빠르게 대응이 가능하도록 유인으로 활용할 수 있다
통계를 올바르게 사용하는 방법¶
“분석은 잘못쓰면 새빨간 거짓말, 잘쓰면 누구도 알 수 없는 강력한 무기”
“거짓말에서 출발한 스스로의 무결점 입증과정”
모집단의 편향: 타인으로부터 어떤 모집단의 표본을 받았을 때, 그 타인의 이해관계를 살펴야 한다
경제인연합회에서 제공하는 불법시위 데이터와 민주노총에서 제공하는 불법시위 데이터는 다른 결과를 유발할 수 있다
전혀 이해관계가 없는 집단에서 추출한 데이터를 활용하거나 누구도 믿을 수 없다면 직접 추출해야 한다
샘플의 편향: 아무리 공정하게 추출하려고 해도 편향이 없을 수 없음을 인지해야 한다
똑같은 설문지에 똑같은 질문을 하더라도 고령 남성이 질문할 때와 젋은 여성이 질문할 때 답이 다를 수 있다
질문지가 특정 답변을 유도하도록 설계되었다면, 그로 인해 수집된 데이터는 신뢰하기 어렵다
아이스크림을 좋아하는지 질문도 여름이냐 겨울이냐에 따라 결과는 달라진다
수집오류의 편향: 사람의 심리가 배제되는 조사 방식이라도 편향이 생길 수 있다
카지노 룰렛 머신의 빨간공과 검은공의 반지름이 미미하게 다를수도 있다
모든 공이 똑같아도 기계의 재질이나 미끄러움은 일정하지 않을 수 있다
공도 기계도 문제가 없더라도 룰렛근처 콧김 하나라도 결과를 바꿀 수 있다
카지노가 있는 지역에 수맥이 있어 미세하게 자기장의 편향으로 결과가 바뀔 수 있다
편향 제거는 불가능에 가깝지만 편향 정도를 측정하고 이해하고 억제하는 기술은 통계에서 중요한 방향 중 하나이다
필연성 증명 불가: 통계적 분석 결과는 아무것도 장담하지 않는다
분석 결과는 높아봐야 95% 또는 99%의 신뢰성을 가질뿐 절대 100%에 도달할 수 없다
99%라고 해도 이는 모든 가정들이 옳았고, 그래서 CLT가 제대로 작동했다는 가정을 전재로 한다(가정이 틀렸다면?..)
글로벌 금융기관들은 99.9% 위험대 대비하도록 정책법을 적용하고 있음에도 리먼 브라더스 파산은 일어났다
이는 0.1%의 사건이 벌어진거라고 할 수 있을까? 대부분 전문가들은 100% 일어날 필연적 사건이라고 한다
두 집단의 관계가 유의미하더라도, 우연히 맞아떨어진 것 이거나 실제로 아무 상관이 없을 수도 있다
기술 보다 객관적 근거들을 늘려가는 과정: 올바른 통계분석 및 활용은 통계에만 의존하지 않는 자세다
분석의 바람직한 순서는 우선 어떤 현상을 잘 관찰/인지하고 잘 생각해서 어떤 결론을 도출하는 것이다
그 후 통계를 활용하여 이 결론을 증명하려는 것이다
반대로 통계분석으로 어떤 현상(또는 인싸이트)을 우연히 발현한 후 왜 그런지 결론을 지을 수도 있다
이는 통계가 필연성을 증명하지 못하다 보니 근거부족 문제에서 벗어나기가 어렵다
더욱 다양한 형태의 통계분석으로 근거를 보강하고 통계가 아닌 다른 기법들로도 지속적으로 근거를 보강해야 한다
통계의 장점/한계를 인지하고 통계가 필연성을 증명하지 못한다는 사실을 반드시 명심하는 것이다
데이터싸이언티스트 스킬셋 3종¶
1) 데이터분석 관련지식(이론)
2) 프로그래밍 활용능력(실습)
3) 설득 및 설명능력(현실)
1) 데이터분석 관련지식(이론)
순수 인문학 또는 예술과 관련된 학문이 아니면 대부분 “수학”과 “컴퓨터”는 모든 학문에서 적극 활용되는 도구
수학
컴퓨터공학
통계학
경영과학
계량경제학
금융공학
물리학
각종 엔지니어링
2) 프로그래밍 활용능력(실습)
엑셀과 통계분석 툴로도 가능하지만, 모든 상황에 유연한 대응과 자동화를 위해 최소 1개이상의 언어능력 필요
3) 설득 및 설명능력(현실)
인문학적 소양: 데이터 해석 + 가치발견 + 가설검증 + 상대에게 설명
시각화: 기술과 예술의 중간단계로 미적감각 + 연습 + 컴퓨터활용능력
프리젠테이션: 설명 능력으로 상대가 듣고싶은 주제발견 + 표현문구 연구 + 스토리라인 구현 + 컴퓨터활용능력 (내말에 현혹시키기 위함이 아님)
분석 단계별 의사결정을 위한 수학/통계적 언어를 이해하기¶
데이터 관점에 따른 분류¶
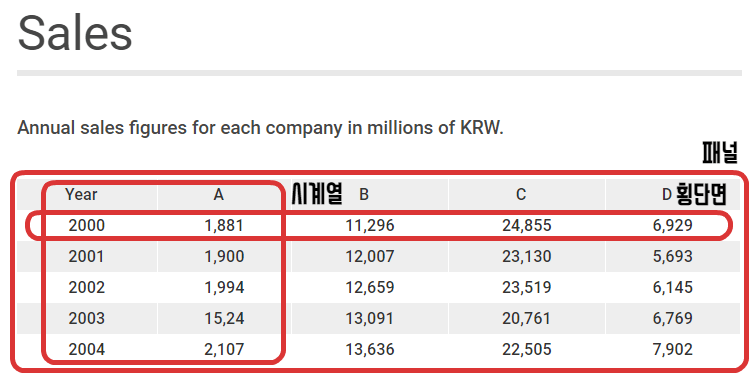
시계열분석 Target 데이터: 최소 시계열/시계열횡단면/패널 데이터 (횡단면 데이터 시계열분석 불가)
시계열분석 시간축: 초/분/시/일/월/년 등 (Tick 단위 이하 및 빛의 속도 이상 제외)
‘ |
횡단면 데이터(Cross Sectional) |
시계열 데이터(Time Series) |
시계열 횡단면 데이터(Pooled Cross Section) |
패널 데이터(Panel) |
|---|---|---|---|---|
정의 |
특정시점 + 다수독립변수 |
다수시점 + 특정독립변수 |
다수독립변수 + 다수시점 |
다수독립변수 + 다수시점 (동일 변수 및 시점) |
예시 |
2016년 16개 시도의 GRDP와 최종소비 |
연도별 전국 GRDP와 최종소비 |
연도별 16개 시도의 GRDP와 최종소비 |
연도별 16개 시도의 GRDP와 최종소비 |
특징 |
값 독립적, 모집단 중 특정 시점 표본추출 |
값 Serial-correlation/Trend/Seasonality 등 |
시점/변수 불일치로 공백 가능 |
시점/변수 일치로 연구자들이 가장 선호 |
데이터 변수구분 및 개념정리¶
원데이터(Raw Data): 수집된 차례로 기록되어 처리되지 않고 순서화되지 않은 데이터 (ex. Log, Table)
변수(Variable): 정보가 수집되는 특정한 개체나 대상 (보통 열(Column) 값들을 의미)
질적변수 vs 양적변수: 데이터의 특성에 따른 분류
질적변수(Qualitative Variable): 변수의 값이 비수치적 특정 카테고리에 포함 시키도록 하는 변수 (ex.색상, 성별, 종교)
명목변수(Nominal Variable): 변수의 값이 특정한 범주(Category)에 들어가지만 해당 범주간 순위는 존재하지 않는 것 (ex.혈액형)
순위변수(Ordinal Variable): 변수의 값이 특정 범주에 들어가면서 변수의 값이 순위를 가지는 경우 (ex.성적)
양적변수(Quantitative Variable): 변수의 값을 숫자로 나타 낼 수 있는 변수 (ex. 키, 몸무게, 소득)
이산변수(Discrete Variable): 하나하나 셀 수 있는 변수 (ex.정수)
연속변수(Continuous Variable): 이산변수와 다르게 변수의 값 사이에 무수히 많은 또 다른 값들이 존재하는 경우 (ex.실수)
등간변수: 변수들 순서뿐만 아니라 순서 사이의 간격을 알 수 있는 변수
비율변수: 등간변수의 특성에 더하여 측정데이터 간의 비율계산이 가능한 변수
독립변수 vs 종속변수: 데이터의 관계에 따른 분류
독립변수(Independent Variable): 다른 변수에 영향을 미치는 변수
종속변수(Dependent Variable): 다른 변수에 영향을 미치지 못하고 다른 변수의 영향을 받는 변수
통계 기본용어 (Descriptive Statistics)¶
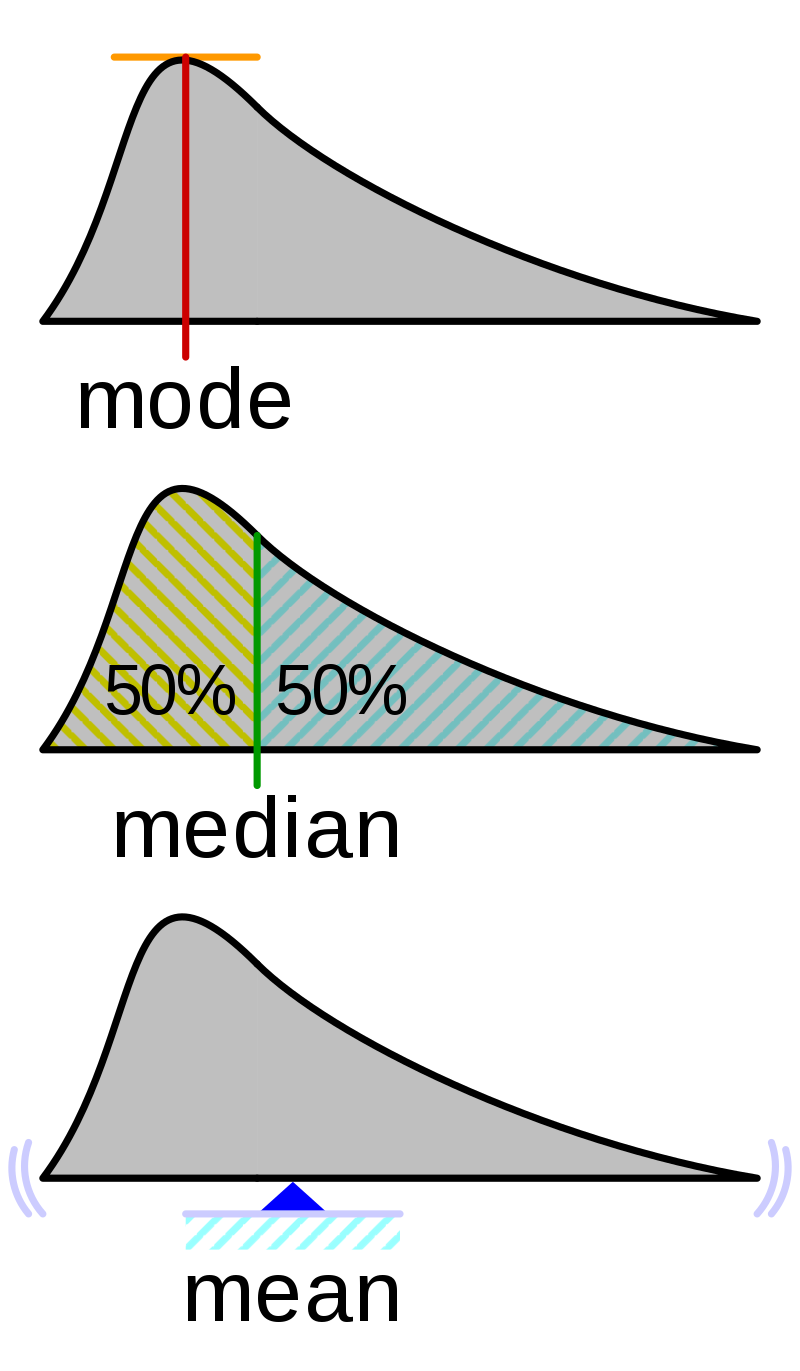
중심 통계량: 데이터의 중심경향을 나타내는 수치¶
평균(Average): 표본데이터의 중심무게 (산술평균, 기하평균, 조화평균, 가중평균)
중앙값(Median): 순서를 가진 표본데이터의 가운데(50%)에 위치한 값
최빈값(Mode): 표본데이터 중 가장 빈번한 값
변동 통계량: 데이터의 변동성을 나타내는 수치¶
범위(Range): 최대값과 최소값의 차이
편차(Deviation): 관측값과 평균의 차이
변동(Variation): 편차 제곱의 합
분산(Variance): 편차 제곱의 합을 데이터의 수로 나눈 값
표준편차(Standard Deviation): \(\sqrt{분산}\)

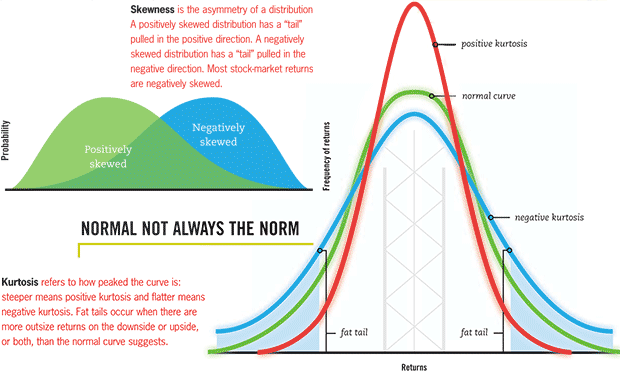
형태 통계량: 데이터의 분포형태와 왜곡을 나타내는 수치¶
왜도(Skewness): 평균을 중심으로 좌우로 데이터가 편향되어 있는 정도
첨도(Kurtosis): 뾰족함 정도
이상치(Outlier): 오류로 판단하는 값이지만 기준이 불명확
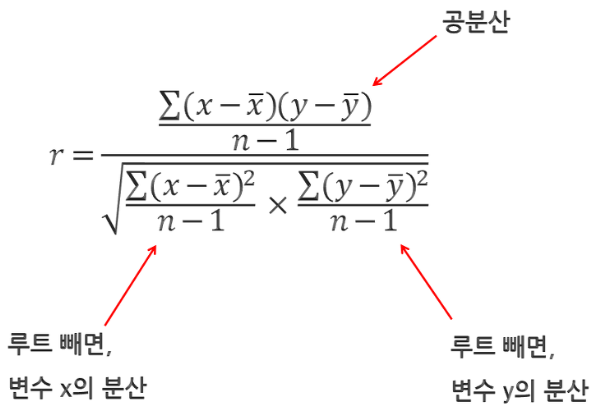
관계 통계량: 데이터간의 관계를 나타내는 수치¶
상관관계(Correlation): A변수의 변화와 B변수의 변화방향의 (선형적)유사성으로 표준화된 공분산이라고도 함
인과관계(Causality): A변수와 B변수중 하나는 원인이 되고 다른 하나는 결과가 되는 관계성
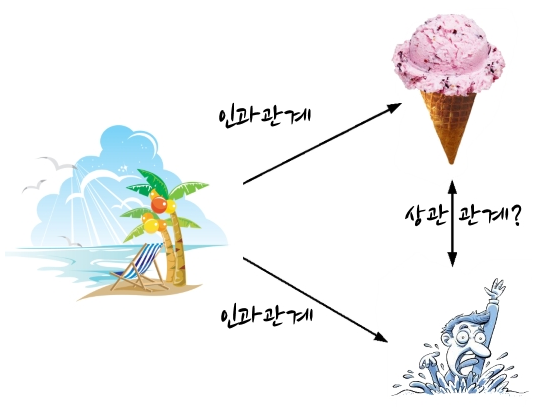
예시:
아이스크림 판매량 vs 익사자의 수
화재 현장에 출동하는 소방대원 수 vs 화재의 규모
해적의 수가 감소됨과 동시에 지구 온난화가 증가됨
함정¶
통계를 이용한 조작: 특정하게 skew된 sample 수집, 임의로 outlier를 정해서 값변경
기존주장과 신규주장의 비교(가설검정)¶
필요성1: 대부분의 분석은 “누구나” 할수 있는 “비교(A/B Test)”를 기반으로 하며, 일상생활부터 연구논문까지 다양
필요성2: “설명력”과 “(모델)복잡도”는 반비례하는 경향이 있으며, 설명력이 수반되는 모델들은 가설검정 해석이 필수
분석목적예시: 양치기들이 거짓말쟁이인가?
나의주장(B): 양치기들은 거짓말쟁이다!
대중주장(A): 양치기들은 거짓말쟁이가 아니다!
가설설정 조건 3가지:¶
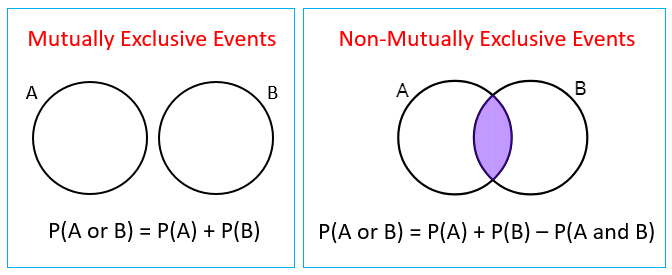
상호배반적(Mutually Exclusive): 나의주장과 대중주장은 모호함 없이 독립적이어야 하며 더하면 다른주장은 없어야 함
거짓말쟁이를 어떻게 정의하지? 어느 수준이 거짓말쟁이라는거지?
나의주장: 양치기들은 다 거짓말쟁이다!
대중주장: 모든 양치기들이 다 거짓말쟁이는 아니다!
증명가능성(Demostrable): 성급한 일반화에 빠지지 않으려면 증명 가능한 것이나 범위로 내세워야 함
모든 양치기들을 확인하기도 어렵고 일부 양치기들 중에는 거짓말쟁이가 아닌 양치기도 있을 수 있음
모든 양치기를 조사후 거짓말쟁이가 없다 하더라도 과거에는 거짓말 했을 수도 있음
나의주장: 현재 대한민국에 있는 양치기들은 일반적으로 거짓말하는 경향이 있다!
대중주장: 그들이라고 일반적으로 더 거짓말을 하는 경향이 있지는 않다!
구체적(Specific): 충분히 구별되고 실현가능한 표현으로 정의되어야 함
나의주장: 현재 대한민국에 있는 양치기들은 일반인 대비 거짓말을 많이 한다!
대중주장: 현재 대한민국에 있는 양치기들은 일반인 대비 거짓말을 많이 하지 않는다!
가설변경에 따라 데이터분석이 변경됨!
가설검정 정리 및 절차:¶
모집단(Population): 연구(관심) 대상이 되는 전체 집단
표본(Sample): 모집단에서 선택된 일부 집단
전수조사(Population Scale Test): 모집단 모두를 조사하는 방식으로 시간과 비용이 가장 비효율적인 방식 (ex.인구주택 총조사)
표본조사(Sample Scale Test): 표본집단을 조사하는 방식으로 시간과 비용을 크게 줄일 수 있으나 편향성(Bias) 문제 존재 (ex.출구조사, 여론조사)
추론통계(Statistical Inference): 모집단에서 샘플링한 표본집단을 가지고 모집단의 특성을 추론하고 그 신뢰성이 있는지 검정하는 것
요즘은 내가 보유한 데이터를 표본으로, 보유하지 못하는 현실세계 전체의 데이터나 미래의 데이터를 모집단으로 보기도 함
표본을 통해 모집단을 추정하기 때문에 표본의 특성이 모집단을 잘 반영해야 함
표본의 기초통계(Descriptive Statistics) 확인을 통해 분포를 확인해야 함 (분포에 따라 분석 방법이 달라짐)
모집단: 현재 전 세계 사람
샘플집단: 현재 대한민국 사람
샘플집단1: 현재 대한민국 양치기들
샘플집단2: 현재 대한민국 일반인들
통계량(Statistic): 표본의 특성을 나타내는 수치
모수(Parameter): 통계량을 통해 알게 된 모집단의 특성
표본오차(Sampling Error): 표본평균으로 모평균을 알아내는 것이 추론통계의 목적이기 때문에 “모평균-표본평균”으로 계산
모평균은 모집단에서 표본추출을 통해 얻어진 표본평균으로 추정된 모집단의 특성이며, 절대 표본평균이 모평균을 그대로 나타내는 것은 아님!
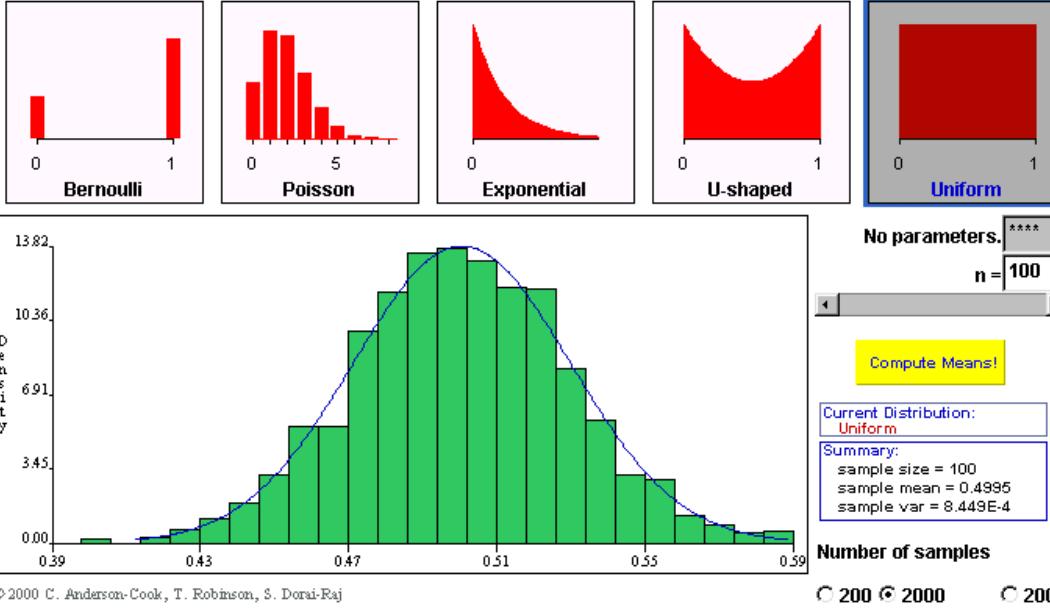
중심극한정리(Central Limit Theorem):
“전체 모집단에서 여러 번 Sample을 추출해라. 그리고 Sample마다 평균을 구해라.
이 평균들의 분포는 정규분포이며 전체 모집단의 평균으로 수렴한다.” $\({\bar{X} \overset{\alpha}{\sim} N(~\mu, \frac{\sigma^2}{n})}\)$모집단이 어떤 분포든 “Sample 평균”의 분포는 정규분포다.
“Sample 크기”가 클수록 “Sample 평균”의 분산은 낮아진다.
“Sample 분산”은 대체로 원집단 분산에 매우 근접한다.
Sample 평균과 분산만으로 모집단의 평균과 분산을 추론할 수 있다.
CLT를 통한 추론으로 모집단의 분포 형태까지 추론하지는 못한다.
(*모집단과 표본집단 비교 대신 표본집단간 비교 수렴에도 성립한다)
“나의주장이 틀렸다면,”
- 양치기들과 일반인들의 거짓말 빈도가 전혀 차이가 없어야 함
- 모든 양치기들을 조사하지 않더라도 Sample로 추출한 양치기의 거짓말 횟수 평균은 일반인의 거짓말 횟수 평균에 수렴해야 함
- 양치기의 거짓말 횟수 평균이 일반인의 거짓말 횟수 평균보다 같거나 적어야 함
1. 가설 설정
대립가설(Alternative Hypothesis, \(H1\)): 나의주장, 분석 방법별 정해져 있음(보통 차이가 있다/영향력이 있다/연관성이 있다/효과가 있다)
대립가설: 현재 대한민국에 있는 양치기들은 일반인 대비 거짓말을 많이 한다!
귀무가설(Null Hypothesis, \(H0\)): 대중주장, 분석 방법별 정해져 있음(보통 차이가 없다/영향력이 없다/연관성이 없다/효과가 없다)
귀무가설: 현재 대한민국에 있는 양치기들은 일반인 대비 거짓말을 많이 하지 않는다!
2. 검정통계량 및 유의확률 추정
검정통계량(Test Statistics): 대립가설(나의주장)과 귀무가설(대중주장)을 비교하기 위한 검증(Evaluation)지표값, 일명 “점추정”
검정통계량: \({샘플집단~~양치기~~거짓말~~빈도~~-~~샘플집단~~일반인~~거짓말~~빈도 \over 샘플집단~~양치기~~거짓말~~빈도~~표준편차}\)
양치기와 일반인의 거짓말 빈도가 차이가 없다면 이상적인 검정통계량은 0이고 나의주장 틀린 것
양치기와 일반인의 거짓말 빈도가 차이가 있다면 검정통계량이 0에서 많이 벗어날수록(큰 양수) 나의주장 옳은 것
검정통계량 로직:
두 표본평균의 분포를 보려고 하면 분석이 어렵기 때문에, “두 표본의 차”만을 분석하면 간단해짐
X와 Y를 각각 추정하는 것보다 X-Y만 추정하면 훨씬 단순한 모형
정규분포에서 정규분포를 빼도 정규분포
<center><img src='Image/Comparison_Test.png' width='600'></center>
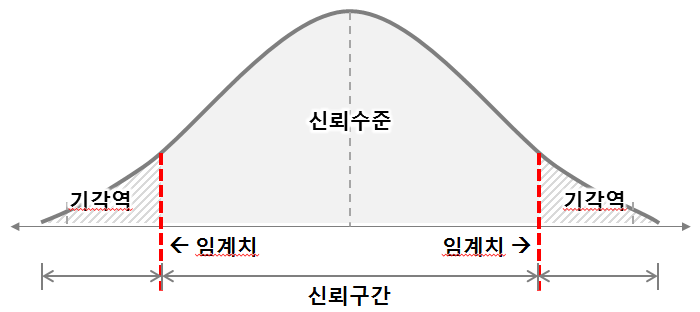
신뢰구간(Confidence Interval): 검정통계량이 발생가능한 구간, 일명 “구간추정”
유의수준(Significant Level, \(\alpha\)):
귀무가설(대중주장)이 참이라는 전제 하에, 대립가설(나의주장)이 참이라고 “오판”할 최대 확률
유의수준 5%:
양치기와 일반인의 거짓말 차이가 없다는 전제 하에,
일반적으로,
100번 중 95번은 귀무가설이 관찰되고(양치기와 일반인의 거짓말 차이가 없음),
100번 중 5번은 대립가설이 관찰된다(양치기와 일반인의 거짓말 차이가 있음)
신뢰수준(Confidence Level): 1-유의수준
4. (나의주장) 기각/채택 의사결정
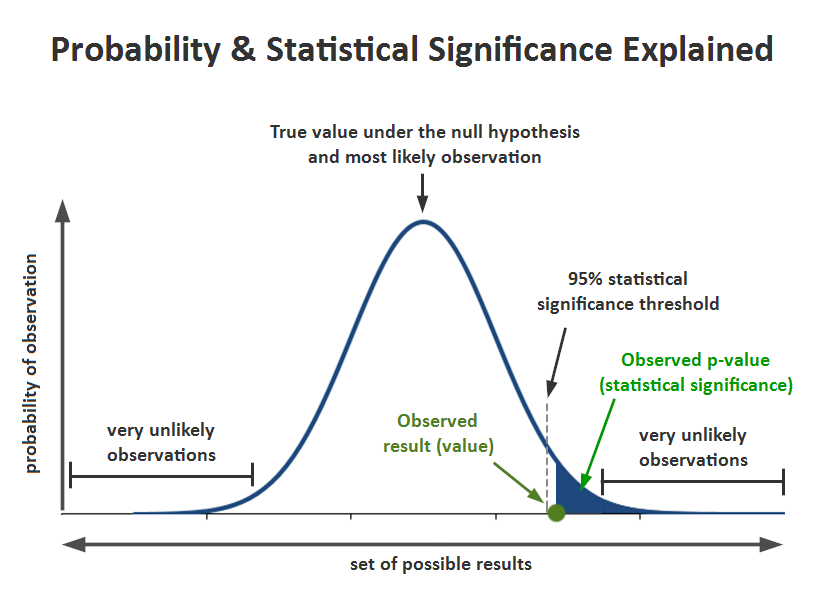
유의확률(p-value):
귀무가설(대중주장)이 참이라는 전제 하에, 대립가설(나의주장)이 관찰될 확률
유의확률 10%:
양치기와 일반인의 거짓말 차이가 없다는 전제 하에,
나의 데이터는,
서로의 거짓말 차이가 있다 오판할 확률(5%) < 서로의 거짓말 차이가 관찰될 확률(10%),
양치기와 일반인의 거짓말 차이가 없다!(귀무가설(대중주장) 채택)
유의확률 1%:
양치기와 일반인의 거짓말 차이가 없다는 전제 하에,
나의 데이터는,
서로의 거짓말 차이가 있다 오판할 확률(5%) > 서로의 거짓말 차이가 관찰될 확률(1%),
양치기와 일반인의 거짓말 차이가 있다!(대립가설(나의주장) 채택)
양측검정/좌측검정/우측검정:
양측검정 |
좌측검정 |
우측검정 |
|---|---|---|
|
|
|
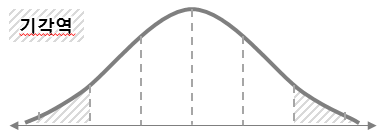
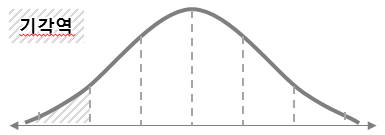
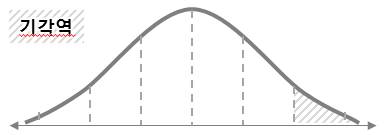
예시 및 정리¶
> 이해문제1: 양치기들이 거짓말쟁이인가?
가설설정
대중주장: 현재 대한민국에 있는 양치기들은 일반인 대비 거짓말을 많이 하지 않는다!
나의주장: 현재 대한민국에 있는 양치기들은 일반인 대비 거짓말을 많이 한다!
점추정 및 구간추정
검정통계량(점추정): \({샘플집단~~양치기~~거짓말~~빈도~~-~~샘플집단~~일반인~~거짓말~~빈도 \over 샘플집단~~양치기~~거짓말~~빈도~~표준편차}\) (1회성)
신뢰구간(구간추정): 실험을 여러번 반복해서 거짓말차이(검정통계량)의 히스토그램 또는 분포 (반복성)
유의수준 및 유의확률
유의수준: (대중주장이 참인 가정에서, 검정통계량 값으로 나의주장이 맞다 오판할 확률)
: 양치기와 일반인이 거짓말 차이가 없다는 전제에서, 양치기들이 일반인보다 거짓말 빈도가 많다 오판할 확률유의확률: (대중주장이 참인 가정에서, 검정통계량 값으로 나의주장이 관찰될 확률)
: 양치기와 일반인이 거짓말 차이가 없다는 전제에서, 양치기들이 일반인보다 거짓말 빈도가 많이 관찰될 확률
의사결정: (유의수준 5%기준)
나의주장 참: 5%보다 작은 경우를 희박한 상황이라고 할때, 나의 데이터에서 나의주장이 관찰될 확률(3%)은 희박한 결과를 발견하였으니 양치기들은 거짓말쟁이!
대중주장 참: 5%보다 작은 경우를 희박한 상황이라고 할때, 나의 데이터에서 나의주장이 관찰될 확률(7%)은 희박하지 않은 결과를 발견한 것이라 양치기들은 거짓말쟁이가 아님!
> 이해문제2: (논문읽기 A/B Test) 내 알고리즘의 성능은 좋은가?
가설설정
대중주장: 지금까지 존재하는 알고리즘의 정확성은 최대 80%
나의주장: 내가 만든 알고리즘의 정확성은 90%
점추정 및 구간추정
검정통계량(점추정): 지금까지 존재하는 알고리즘들로 나올수 있는 정확성 (1회성)
신뢰구간(구간추정): 정확성을 여러번 반복해서 계산 시 정확성의 히스토그램 또는 분포 (반복성)
유의수준 및 유의확률
유의수준: 일반적인 알고리즘 정확성이 최대 80%일 거라는 가정하에, 알고리즘 정확성이 90%이라 “오판”할 확률
유의확률: 일반적인 알고리즘 정확성이 최대 80%일 거라는 가정하에, 나의 실험에서 정확성이 90%가 관찰될 확률
의사결정: (유의수준 5%기준)
나의주장 참: 5%보다 작은 경우를 희박한 상황이라고 할때, 나의 실험에서 90% 정확성이 관찰될 확률은 3%로 희소한 범위 내 있으니 나의 주장이 맞고 내가 만든 알고리즘은 훌륭한 알고리즘!
대중주장 참: 5%보다 작은 경우를 희박한 상황이라고 할때, 나의 실험에서 90% 정확성이 관찰될 확률은 7%로 희소한 결과가 아니니 대중 주장이 맞고 내가 만든 알고리즘은 일반적인 알고리즘!
> 심플정리1: 에너XXX 건전지 수명이 듀XX 보다 길다?
가설확인:
대중주장(H0): 에너XXX 수명 = 듀XX 수명
나의주장(H1): 에너XXX 수명 > 듀XX 수명
유의수준 설정 및 유의확률 확인:
유의수준: 5%
유의확률: 1% (H0가 참이란 가정에, 건전지 평균 수명(검정통계량) 100개를 실험)
의사결정
유의수준 > 유의확률: 나의주장 참!
-> 에너XXX 수명이 더 김유의수준 < 유의확률: 대중주장 참!
-> 에너XXX 수명이 더 길지 않음
> 심플정리2: 숟가락을 잘 구부리는 나는 초능력자다?
가설확인:
대중주장(H0): 내 능력 = 다른 사람의 능력
나의주장(H1): 내 능력 > 다른 사람의 능력
유의수준 설정 및 유의확률 확인:
유의수준: 5%
유의확률: 8% (H0가 참이란 가정에, 숟가락 구부린 횟수(검정통계량) 100명과 비교)
의사결정
유의수준 > 유의확률: 나의주장 참!
-> 나는 초능력자!유의수준 < 유의확률: 대중주장 참!
-> 나는 일반인!
> 현실문제1: 회귀분석 (점추정 & 구간추정 & 결과해석)
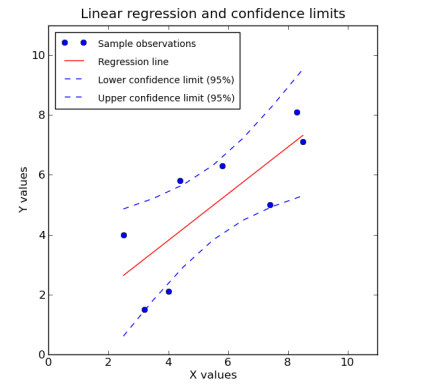
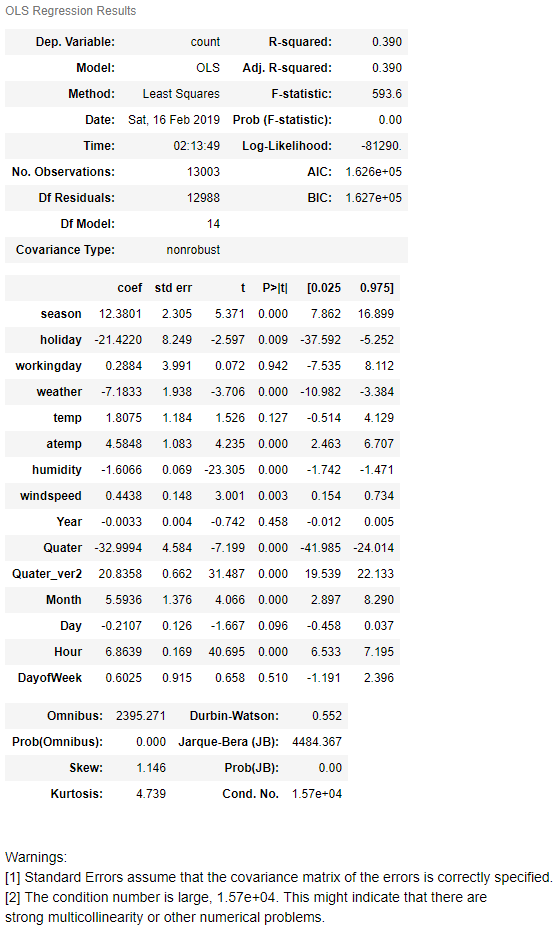
> 현실문제2: 출구조사
(방송표현) “출구조사 결과 A후보의 지지율은 40%로 추정되며, 95% 신뢰구간에서 +-3%의 오차가 발생할 수 있습니다”
(통계표현) “샘플링을 통해 A후보의 지지율(검정통계량)의 평균값은(점추정) 40%이며, 실제 모집단 확대시 A후보의 지지율이 37%~43%(구간추정)에 있을 확률이 95%이다”
표본 추출(샘플링)의 중요성 및 대응¶
중요성1. 모든 통계적 분석은 샘플이 모집단을 대표할 수 있다는 가정!
: 모집단의 특성을 통계로 설명하는 것은 제법 괜찮은 접근이지만, 샘플이 모집단을 대표하지 못하면 거짓말 분석결과(유의미하지 않은 통계)
중요성2. 빅데이터라고 하더라도 결국 편향이 없을 수 없는 샘플!
: 많은 전문가들이 통계의 한계를 전문적인 이유로 설명하지 못하더라도 본능적으로 왜곡될 수 있음을 인지하고 있고, 아무리 공정하게 추출하려 해도 편향이 없을 수 없음을 인지해야 함
장점: 과학적 연구에서 표본조사가 전수조사보다 선호되는 이유
정보가 신속하게 필요한 경우, 데이터수집, 분석을 신속히 처리
신속한 의사결정시간에 따른 비효율을 줄이고 비용과 시간이 절약되어 경제적
샘플링 데이터의 정확도에 영향을 주는 오차는 “표본추출오차”와 “비표본오차”가 있는데,
표본추출오차는 샘플링 과정에서 발생하나 표본의 크기를 증가시키면 줄어드는 경향,
비표본오차는 데이터 수집이나 처리, 사람의 주관으로 발생하는 오차로 전수/표본조사 모두 존재,
샘플링이 데이터의 수집과정 상의 오류를 더 잘 통제가 가능기에 전수조사보다 비표본오차가 적어 정확도가 높음모집단이 무한히 많거나 정확한 파악이 불가하거나 특정 집단에서만 수집된 데이터의 경우 전수조사가 불가하기에 불가피하게 표본조사를 시행해야 함
단점:
모집단 자체가 작은 경우 표본조사가 무의미 할 수 있음
데이터의 특성을 정확히 모르면서 샘플링을 하면 bias나 왜곡이 더욱 증가될 수 있음
모집단을 완벽하게 대표하는 표본을 선정하는 일은 쉽지 않음(그래도 안하는 것보단 나음)
샘플링 방법론¶
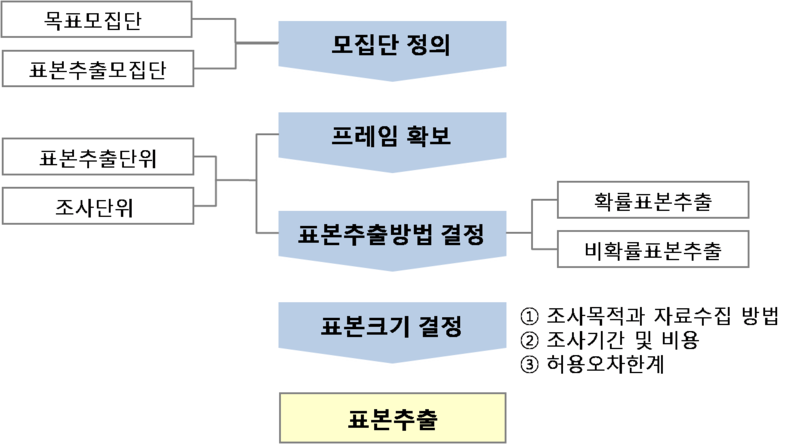
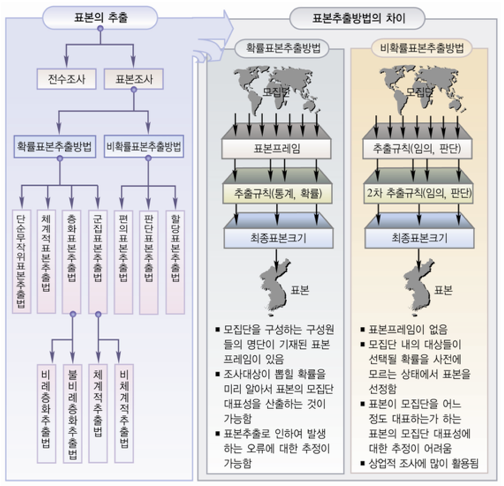
Process:
Comparison:
확률표본(Probability Sample): 무작위추출 |
비확률표본(Nonprobability Sample): 작위추출 |
|
|---|---|---|
방법론 |
주관을 배재하고 각 샘플이 뽑힐 확률을 확률적(객관적)으로 균등하게 부여 => “확률표본” |
샘플이 뽑힐 확률을 수학/확률적인 방법을 따르지 않음 => “비확률표본” |
장점 |
표본이 추출될 확률 사전적으로 알때 용이 |
표본이 추출될 확률 사전적으로 모를때 용이 |
모수추정에 bias가 없음 |
모수추정에 bias가 있음 |
|
추출기회가 독립적이라 대표성이 높음 |
추출기회가 독립적이 않아 대표성이 낮음 |
|
단점 |
시간과 비용이 많이 듦(표본의 크기가 커야함) |
시간과 비용이 적게 듦(표본의 크키가 작아도됨) |
모집단 일반화 |
가능 |
불가능(모집단의 대략적 성격 파악 목적) |
표본오차(신뢰구간) 추정 |
가능 |
불가능 |
종류 |
단순임의 표본추출 |
편의 표본추출 |
체계적 표본추출 |
할당 표본추출 |
|
비례층화 표본추출 |
자발적 표본추출 |
|
다단계층화 표본추출 |
||
군집 표본추출 |
확률표본(Probability Sample) 추출법¶
세부종류:
요약:
종류 |
추출법 |
비고 |
|---|---|---|
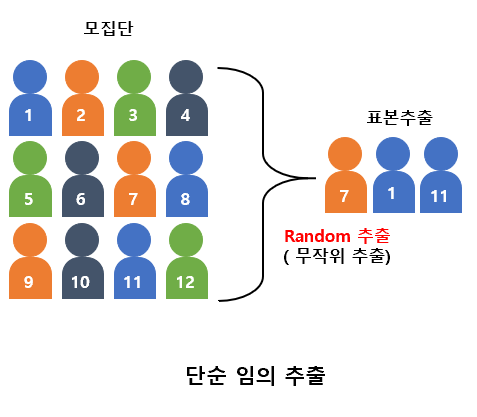
단순임의 표본추출(Simple Random Sampling) |
모집단으로 표본을 균등한 확률로 추출하는 것으로, 추출된 표본을 단순임의표본이라고 함 |
100명(남60,여40) 중 10명을 뽑을 시 전부 남자일 수 있어서 모집단의 특성을 반영하지 못하는 대표성 한계 |
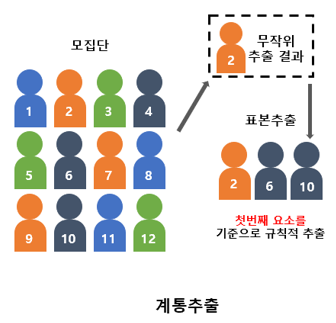
체계적 표본추출(Systematic Sampling) |
첫번째 표본을 무작위로 선정한 후 k번째 간격의 표본들을 선정함 |
단순임의추출의 대표성 한계를 줄이기 위해서이며 비용이 적게들고 정확성이 단순임의 추출보다 높은편 |
k는 모집단의 크기를 원하는 표본의 크기로 나누어 계산 |
||
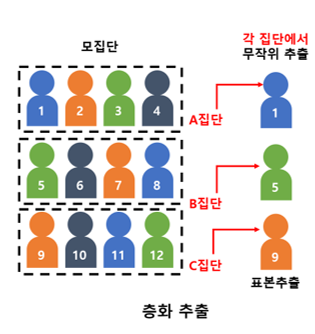
층화 표본추출(Stratified Sampling) |
모집단을 서로 겹치지 않는 여러 개의 층(부분집단)으로 구분 후, 각 층에서 단순임의추출로 표본 추출함 |
단순임의추출의 대표성 한계를 줄이기 위해 여러 층으로 구분하여 bias를 회피 |
층간은 이질적이나 층내는 동질적인 데이터에 적합(ex. 개발 파트 vs 분석 파트) |
||
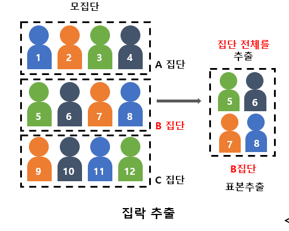
군집 표본추출(Cluster sampling) |
모집단을 서로 인접한 값들로 묶어 집단을 구성후, 특정 집단의 일부 또는 전체를 표본으로 함 |
집단간은 동질적이나 집단내는 이질적인 데이터에 적합(ex. 분석파트1 vs 분석파트2) |
집단간은 동질적이나 집단내는 이질적인 데이터에 적합(ex. 분석파트1 vs 분석파트2) |
비확률표본(Nonprobability Sample) 추출법¶
세부종류:
요약:
종류 |
추출법 |
비고 |
|---|---|---|
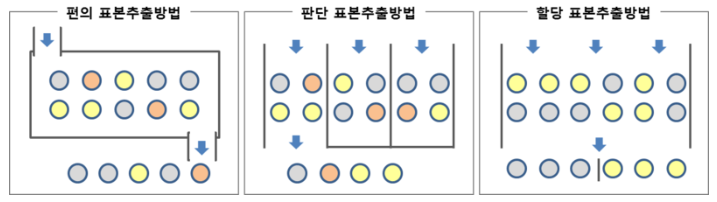
편의 표본추출(Convenience Sampling) |
특정 집단이나, 계층 및 시간대로 데이터만을 대상으로 표본을 선정 |
시간과 비용이 적게 들지만 대표성 문제 아주 높음 |
판단 표본추출(Purposive Sampling) |
분석가 주관으로 분석에 도움이 된다 판단되는 대상만을 표본으로 함 |
전문가여야 가능하며 그렇지 않으면 모집단의 대표성 문제 높음 |
할당 표본추출(Quota Sampling) |
모집단이 여러 특성을 가질 경우 각 특성에 따라 층을 형성 후, 층별로 표본을 같게 또는 비례 선정 |
모집단의 특성을 잘 아는 전문가이어야 하마 그렇지 않으면 대표성 뿐 아니라 Bias 문제 높음 |
요약¶
문제: 선거에서 중년층>청년층=노년층 투표율이 높고, 남성=중산층>여성=저소득층 투표율이 높으면 선거여론조사에서 어떤 데이터를 수집해야 빠른 시간 내 높은 정확성의 출구조사를 분석할 수 있을까?